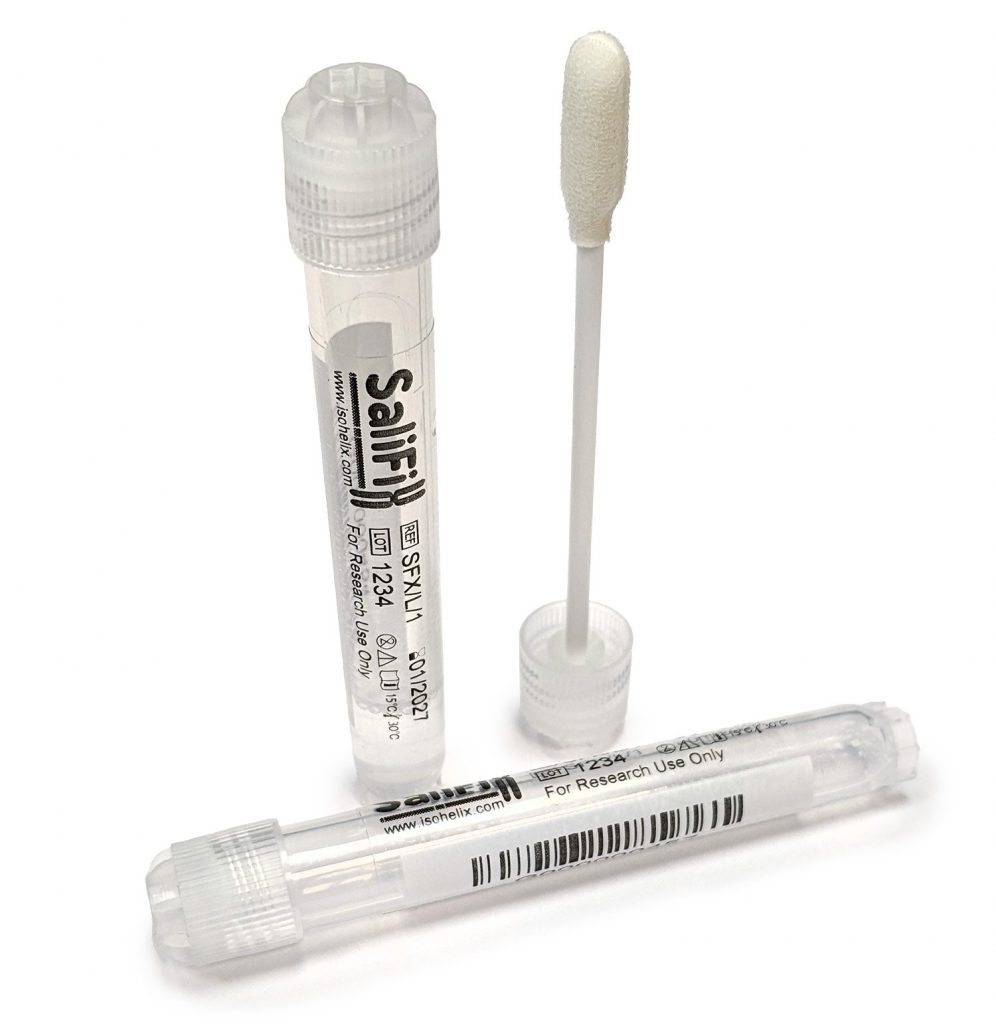
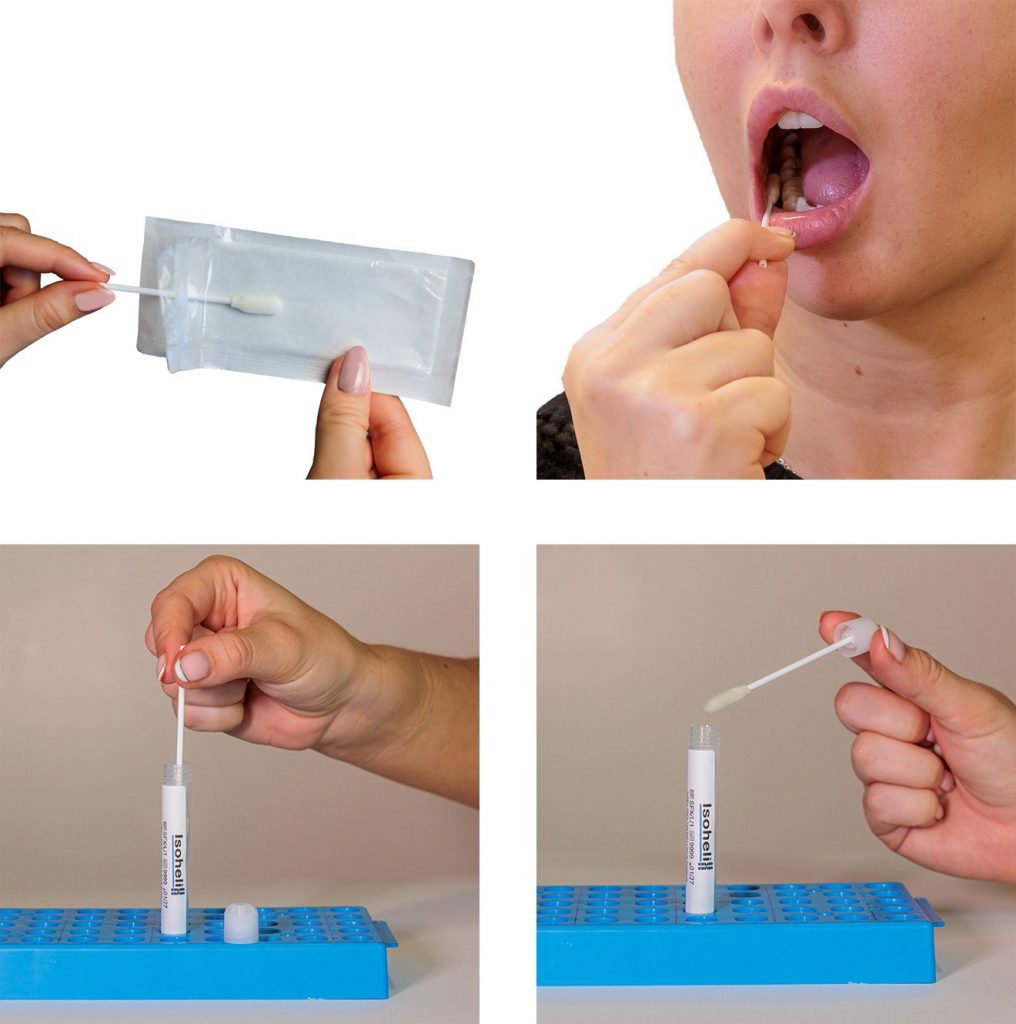
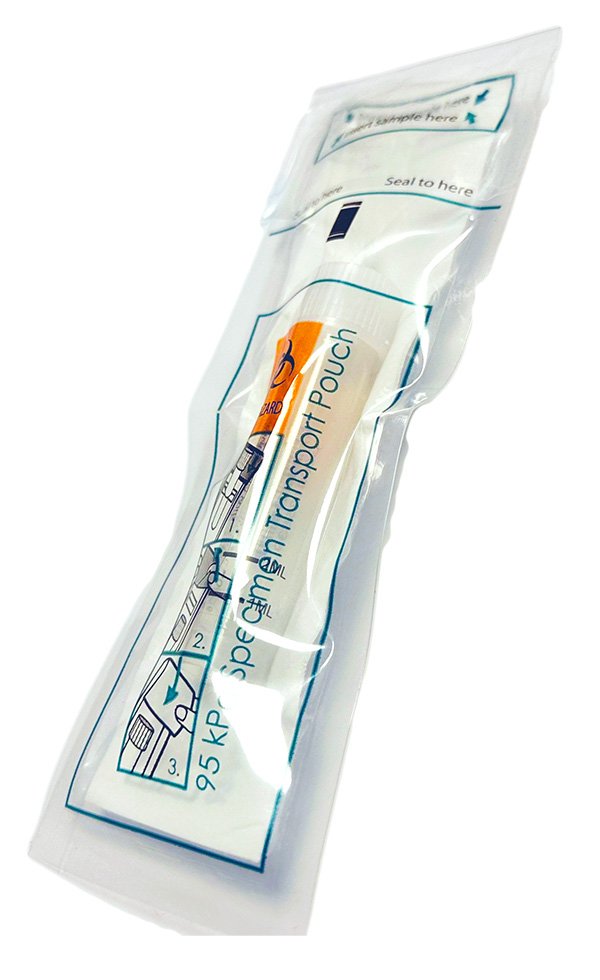
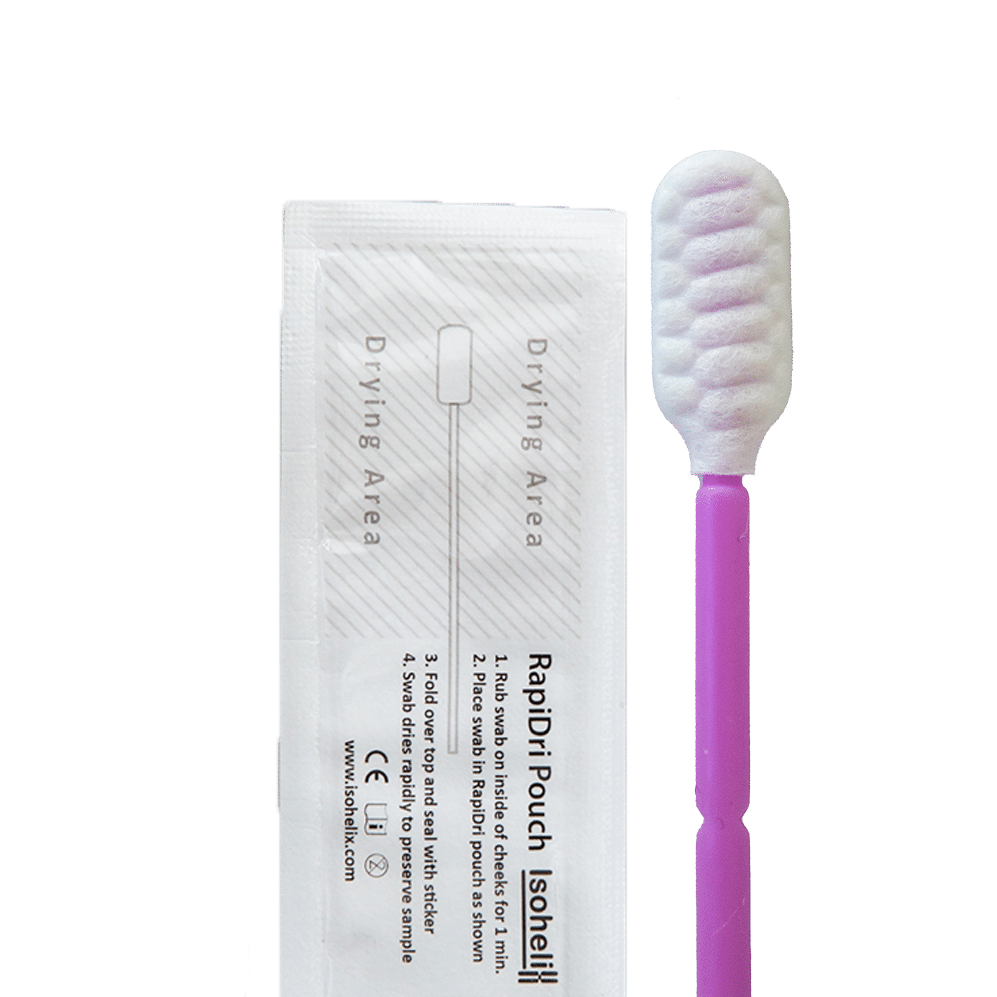
Isohelix products have been used in a large number of peer-reviewed animal population genetics publications, supporting applications including conservation genomics, livestock breeding, biodiversity monitoring, veterinary genetics, and wildlife population studies.
In this blog, we discuss:
- The challenges faced by researchers collecting DNA samples in the field
- Key molecular biology techniques used for animal population genetics
- How to choose which Isohelix DNA sampling and extraction products to use for your animal population genetics study
- Some recent studies using Isohelix products to study a wide range of species, from large mammals to small invertebrates.
Introduction
DNA analysis provides valuable insights into animal health and population structures and is used to understand biodiversity, estimate population size, track population structure and connectivity, and understand evolutionary history.
To study animal populations, researchers often need to collect DNA from rare, wild, or difficult-to-handle animals, often in field conditions away from laboratory infrastructure. For rare or dangerous wild animals, indirect sampling methods are used, for example, taking DNA samples from hair or feces.

For more information on how scientists are using Isohelix products to collect high-quality nucleic acid samples from a range of environments, such as jungles, deserts, and marine environments, see our blog, “How Researchers Use Isohelix Kits in Extreme Environments.”
Which molecular techniques are used to study animal population genetics?
As animal population genetics has evolved, researchers have moved from analyzing a handful of genetic markers using PCR-based methods to genome-wide approaches such as SNP microarrays and next-generation sequencing. The technique used depends on the biological question being asked, the species being studied, and the level of genomic resolution required.
The most commonly used molecular techniques for animal population genetics studies are:
- PCR-based genotyping – used to analyze a small number of genetic markers, e.g., microsatellites, species-specific markers, or SNPs. They are cost-effective and particularly useful for targeted studies in which researchers need to genotype large numbers of samples across a limited number of loci.
- SNP microarrays – Widely used in livestock breeding, conservation genetics, and population structure studies to analyze thousands to hundreds of thousands of genetic markers simultaneously across the genome. Provide a genome-wide view of genetic variation at relatively low cost.
- Next Generation Sequencing (NGS) – NGS technologies generate large-scale genomic datasets ranging from targeted gene panels to whole genomes. They provide the highest resolution for studying genetic diversity, adaptation, evolution, and population structure, and are increasingly becoming the standard approach for animal population genomics.
- Mitochondrial sequencing – Mitochondrial DNA (mtDNA) is inherited maternally and evolves relatively rapidly, making it useful for studying ancestry, population history, and species relationships.

DNA input requirements vary between platforms, library preparation kits, and laboratories. More demanding NGS applications generally require larger quantities of higher-quality DNA, making sample collection, stabilization, and extraction particularly important. In contrast, PCR or mitochondrial sequencing can often tolerate smaller amounts of more degraded DNA.
How to choose which DNA sampling and extraction products to use for your animal population genetics study
With a range of products available for a number of different scenarios, it can be difficult to decide which products to use for your study.
The table below gives suggestions of which Isohelix products to use, in which circumstances:
Table 1: Isohelix Products for Animal Population Genetics Studies
| Workflow Step | Typical Sample Type | Example Applications | Isohelix Product | Key Benefits |
|---|---|---|---|---|
| Sample collection | Buccal epithelial cells from larger animals, faecal surface swabs | Wildlife population genetics, livestock genomics, conservation studies, pedigree analysis | Isohelix Buccal Swabs | High DNA yield, easy field collection, suitable for medium-to-large animals |
| Sample collection | Buccal cells and from small animals | Buccal cells and from small animals Amphibians, reptiles, nestlings, bats, fish, insects and other small organisms | Isohelix Mini Swabs | Designed for small mouths and delicate sampling, minimises animal stress |
| Sample collection | Faecal surface swabs | Non-invasive wildlife population genetics, endangered species monitoring, carnivore and herbivore studies | Isohelix Xtreme DNA Kit | Optimised for challenging low-abundance DNA samples collected from faecal surfaces |
| Sample stabilisation | Buccal and surface swab samples | Stabilising DNA from remote wildlife studies, biodiversity surveys, international field projects | RapiDri Swab Kits | Integrated desiccant stabilisation enables dry, ambient-temperature storage and transport and reduces cross-contamination |
| Sample stabilisation | Buccal swabs and faecal surface swabs | Longitudinal population studies, conservation genomics, biobanking | BuccalFix Stabilisation Buffer | Preserves DNA at ambient temperature for up to two years |
| DNA Extraction | Buccal swabs, saliva and stabilised samples | SNP genotyping, microsatellite analysis, GWAS, population structure studies and sequencing workflows | Isohelix DNA Isolation Kits | Available in spin-column and precipitation formats, optimised for Isohelix collection systems |
To discuss which products would be best for your study, drop us a line at info@isohelix.com
Recent Publications Using Isohelix Products to Study Animal Populations
Published research citing Isohelix products spans mammals, reptiles, birds, amphibians, and invertebrates across multiple continents.
Here are some recent examples of peer-reviewed studies that used Isohelix products.
For more publications featuring Isohelix products, please visit the publications page.
- Penguins:
Isohelix swabs were used to collect fecal samples from nests, which were analyzed by DNA metabarcoding of the eukaryotic mitochondrial cytochrome c oxidase subunit I (COI) gene.

Stanners, A., and A.McGaughran. 2026. “From Nest Box to Neighborhood: Patterns of Island Biodiversity Characterized Through eDNA From Little Blue Penguin (Eudyptula minor) Nest Boxes.” Environmental DNA8, no. 3: e70302. https://doi.org/10.1002/edn3.70302.
- Chameleons:
Isohelix SK-3S buccal swabs enabled non-invasive sampling of a European Chamaeleo africanus population, yielding DNA of sufficient quality for PCR amplification and gene sequencing.

Koutsokali, M., Dianni, C. and Valahas, M. (2023), Buccal swabs as an effective alternative to traditional tissue sampling methods for DNA analyses in Chamaeleonidae. Wildlife Biology, 2023: e01052. https://doi.org/10.1002/wlb3.01052
- Freshwater mussels:
Isohelix DNA Buccal Swabs were used to collect DNA from the foot tissue of a subset of specimens. Swabs were stored in vials containing either 95% non-denatured ethyl alcohol or Buccalfix® DNA Stabilization Buffer. DNA was extracted from swabs using the IsoHelix Xtreme DNA Isolation kit.

Perkins MA, DeVilbiss KL, Whelan NV, Hoch RA, Jones BK, Mays JW, Evans HK, Benfield SB (2025) A new endemic freshwater mussel (Bivalvia, Unionidae) genus and species, Ligodonta obscura, from the Yadkin-Pee Dee River drainage in North Carolina, USA. ZooKeys 1248: 245-265. https://doi.org/10.3897/zookeys.1248.152952
- Elephants:
DNA was extracted from dung piles. Samples were collected from dung in ethanol and from a swab taken from the dung pile and stored in Isohelix buccalfix. A significantly greater number of genotypes could be obtained from DNA extracted from swabs compared with DNA extracted from dung samples in ethanol.SNPs, microsatellites, and a sequence of the mitochondrial genome were analyzed for this study.

Sinovas P, Smith C, Keath S, Chantha N, Kaden J, Ith S, Ball A. 2025. Giants in the landscape: status, genetic diversity, habitat suitability and conservation implications for a fragmented Asian elephant (Elephas maximus) population in Cambodia. PeerJ 13:e18932 https://doi.org/10.7717/peerj.18932